행동 호기심 기반 심층 강화 학습 알고리즘 채택
중국 정저우대학교(Zhengzhou University) 연구팀이 예측 불가능한 교통 상황에서도 자율주행차가 효율적으로 경로를 계획할 수 있는 인공지능(AI) 기반 최적화 방법을 개발했다고 밝혔다.
이 연구 결과는 과학 전문 저널인 '인텔리전트 컴퓨팅(Intelligent Computing)'에 '비결정적 환경에서의 경로 계획을 위한 행동 호기심 기반 심층 강화 학습 알고리즘(Action-Curiosity-Based Deep Reinforcement Learning Algorithm for Path Planning in a Nondeterministic Environment)'이라는 제목으로 게재됐다.
연구팀은 360도 라이다 센서가 장착된 '터틀봇3 와플' 보더 랜드 2 슬롯 머신을 활용한 현실적인 시뮬레이션 플랫폼에서 이 방법을 평가했다. 단순한 정적 장애물 코스부터 동적이고 예측 불가능한 움직이는 장애물이 있는 매우 복잡한 시나리오까지 네 가지 시나리오를 테스트한 결과, 해당 방법은 여러 최신 기준 알고리즘과 비교했을 때 수렴 속도, 훈련 기간, 경로 계획 성공률, 평균 보상 등 주요 지표에서 놀라운 개선을 보였다.
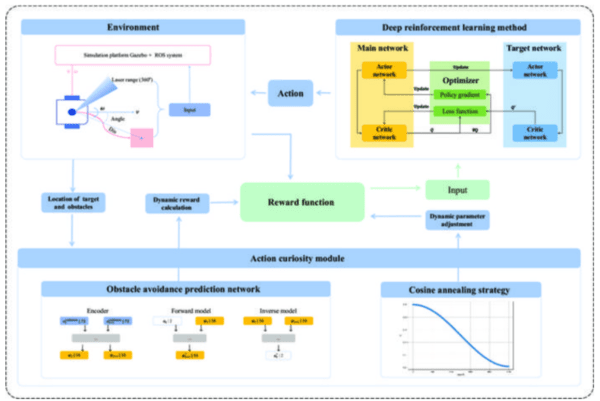
이 방법은 심층 강화 학습에 기반을 두었지만, 심층 강화 학습의 느린 수렴 속도와 낮은 학습 효율성이라는 한계를 극복하기 위해 '행동 호기심 모듈'을 설계하고 프레임워크에 통합했다고 연구팀은 설명했다. 이 모듈을 통해 지능형 에이전트인 보더 랜드 2 슬롯 머신은 광범위한 탐색을 통해 호기심을 충족시키면서도 더 효율적으로 학습하고 보상을 얻을 수 있었다.
행동 호기심 모듈은 에이전트가 중간 난이도의 상태에 집중하도록 유도하여 완전히 새로운 상태를 탐색하는 것과 알려진 보상 행동을 활용하는 것 사이의 균형을 맞췄다. 이 모듈은 장애물 인식 예측 네트워크를 통합하여 전통적인 내재적 호기심 모듈을 확장했다. 예측 네트워크는 장애물과 관련된 예측 오류를 기반으로 동적으로 호기심 보상을 계산함으로써, 에이전트의 주의를 학습 및 탐색 효율성을 극대화하는 상태로 이끌었다.
또한, 훈련 단계에서 발생할 수 있는 과도한 탐색으로 인한 성능 저하를 방지하기 위해 '코사인 어닐링 전략(cosine annealing strategy)'도 사용됐다. 이 전략은 호기심 보상의 가중치를 점진적으로 조정하여 훈련 과정을 안정화하고 학습된 정책의 신뢰할 수 있는 수렴을 가능하게 했다.
연구팀은 앞으로 움직임 예측 기술을 통합하여 이 방법을 개선할 계획이라고 밝혔다. 다음 단계는 매우 역동적이고 확률적인 환경에 대한 적응력을 향상시켜 실제 자율 주행에 보다 견고하고 실용적인 적용 가능성을 모색하는 것을 목표로 한다.